
Zero123
Zero-1-to-3:
Zero-shot One Image to 3D Object
Introduction
- Novel synthesizes views
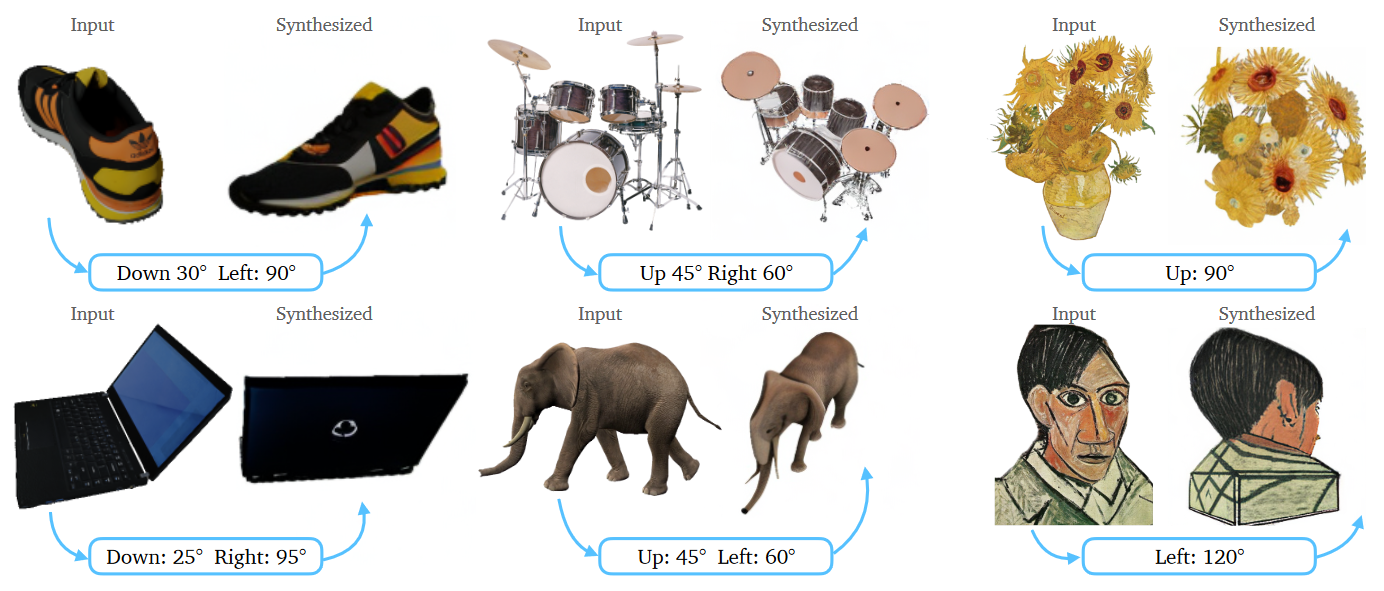
Overview
Manipulate the camera viewpoint in large-scale diffusion models
Learn controls for camera poses during the generation
Diffusion Model
- 正向传播
\[ \begin{aligned} & \text { Noised images } \quad \text { Output Mean } \mu_t \quad \text { Variance } \Sigma_t \\ & q\left(x_t \mid x_{t-1}\right)=\mathcal{N}\left(x_t ; \sqrt{1-\beta_t} x_{t-1}, \beta_t I\right) \end{aligned} \]
Closed form \[ \left.\boldsymbol{x}_t \sim q\left(\boldsymbol{x}_t \mid \boldsymbol{x}_0\right)=\mathcal{N}\left(\boldsymbol{x}_t ; \sqrt{\overline{\alpha_t}} \boldsymbol{x}_0,\left(1-\bar{\alpha}_t\right) \mathbf{I}\right)\right), \quad \bar{\alpha}_t=\prod_{s=1}^t \alpha_s \]
整个前向的后验估计 $$
q(x_{1:T} x_0) = {t=1} ^ T q(x_t x{t-1}) $$
Diffusion Model
- 逆向过程 (Denoise)
\[ \begin{aligned} & p_\theta\left(x_t \mid x_{t-1}\right)=\mathcal{N}\left(x_{t-1} ; \mu_\theta(x_t,t), \Sigma_\theta(x_t,t)\right) \end{aligned} \]
Loss = \(-\log(p_\theta(x_0))\)
下界
\[ L_{\text {simple }}(\theta):=\mathbb{E}_{t, \mathbf{x}_0, \boldsymbol{\epsilon}}\left[\left\|\boldsymbol{\epsilon}-\boldsymbol{\epsilon}_\theta\left(x_t, t\right)\right\|^2\right] \] 其中 \(x_t = \sqrt{\bar{\alpha}_t} \mathbf{x}_0+\sqrt{1-\bar{\alpha}_t} \boldsymbol{\epsilon}\)
U-Net
在每一个训练轮次每个训练样本(图像)随机选择一个时间步长t。
对每个图像应用高斯噪声(对应于t)。
将时间步长转换为嵌入(向量)。
Background
- 3D generative models
- Diffusion Model : 昂贵的标定 3D 数据,未标定的图像, Internet → Bias
- 利用 NeRF : DreamFields, CLIP
- Single-view object reconstruction:
- 显示表示泛化能力差,全局 conditioning
- Zero-shot : 在无需针对训练的情况下给出响应
Motivation
Diffusion Models 的数据集中包含不同视角的图像
引导模型控制相机外参
Learning to control camera viewpoint
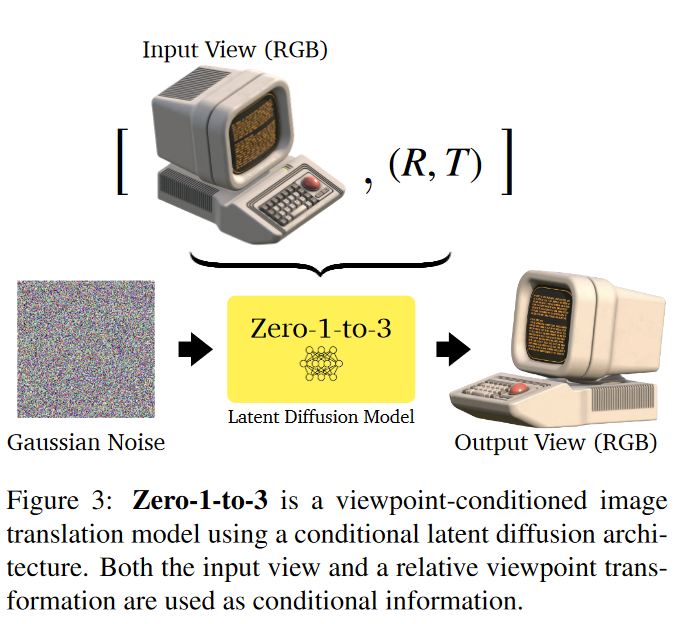
Input: paired images and their relative camera extrinsics \(\{(x,x_{(R,T)}, R, T)\}\)
Latent diffusion
- Encoder \(\varepsilon\)
- Denoiser U-Net \(\epsilon_{\theta}\)
\[ \min _\theta \mathbb{E}_{z \sim \mathcal{E}(x), t, \epsilon \sim \mathcal{N}(0,1)}\left\|\epsilon-\epsilon_\theta\left(z_t, t, c(x, R, T)\right)\right\|_2^2 \]
- Inference model generate from a Gaussian noise image conditioned on \(c(x,R,T)\)
View-Conditioned Diffusion
- CLIP embedding \(c(x,R,T)\)
- cross-attention to condition denoising U-Net
Geometry
- Score Jacobian Chaining (SJC)
- 随机采样视点,做体渲染
- 在图像上添加高斯噪声
- 通过 conditional U-Net
- image x
- embedding \(c(x,R,T)\)
- timestep \(t\)
- PAAS score toward the non-noisy input \(x_{\pi}\)
\[ \nabla \mathcal{L}_{S J C}=\nabla_{I_\pi} \log p_{\sqrt{2} \epsilon}\left(x_\pi\right) \]
Live Demo (Novel synthesizes views)
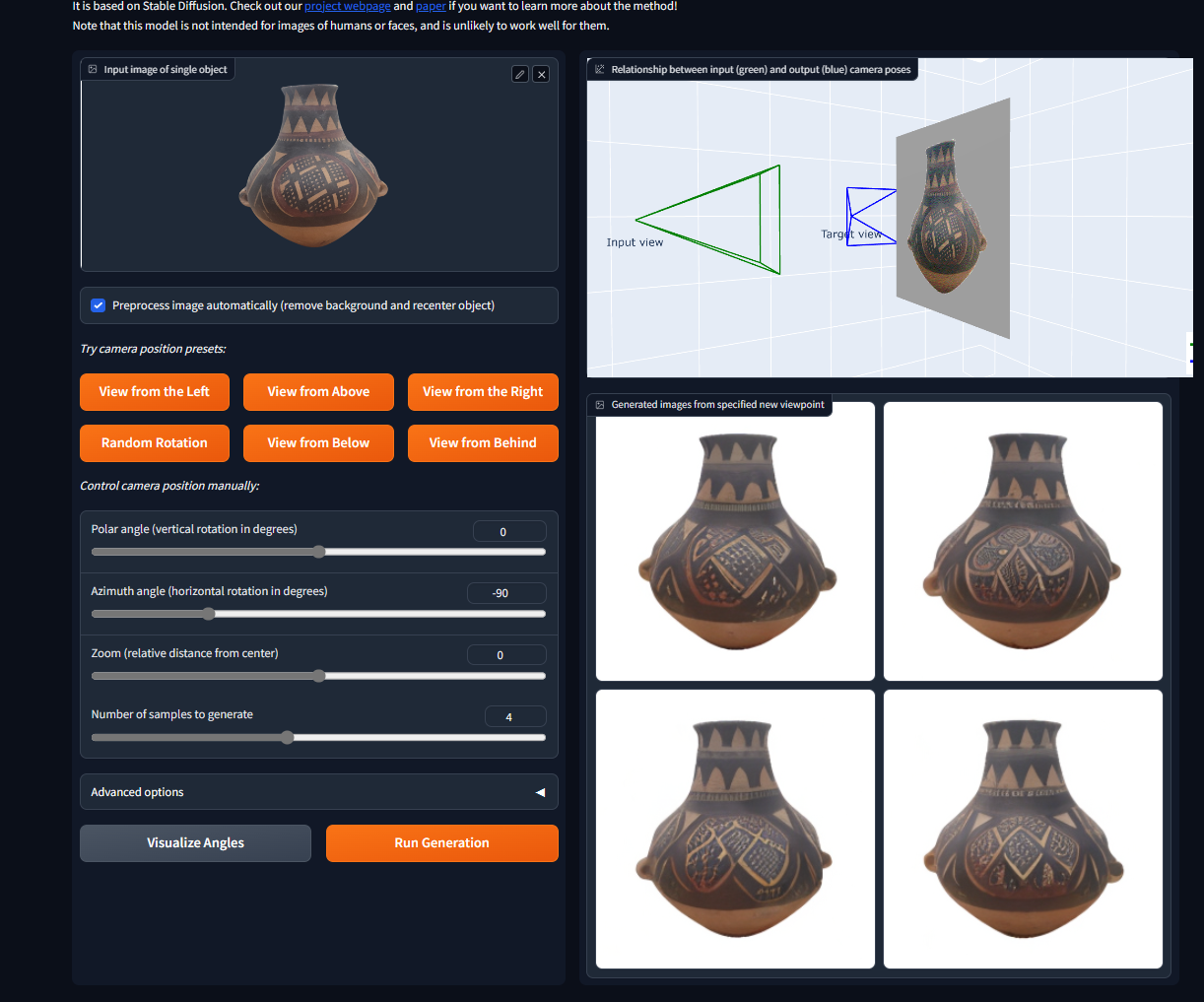
View from above

Left

SJC
Reference
多元正态分布
协方差矩阵
Diffusion 和Stable Diffusion的数学和工作原理详细解释