Neus
Motivation
IDR: 无法处理深度图上的突变,需要 object mask 监督

NeRF 优点: 体积渲染方法能够训练网络找到远处的表面来产生正确的场景表示
Method
we developed a novel volume rendering method to render images from the implicit SDF and minimize the difference between the rendered images and the input images
Rendering Procedure
Scene representation
物体表面 $SDF = 0 $
S-density
logistic density distribution, 标准差为 \(1/s\) ,当网络收敛时, \(1/s\) 收敛于 \(0\).
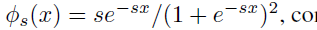
Rendering
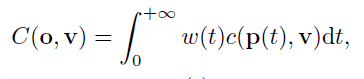
weight function \(w(t)\)
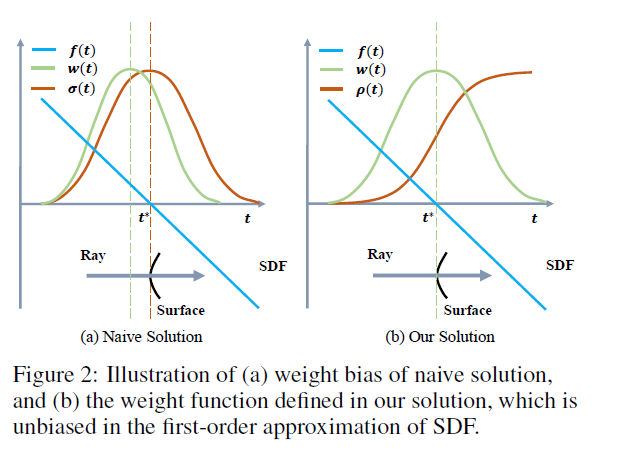
Requirements on weight function
Unbiased . Given a camera ray \(p(t), w(t)\) attains a locally maximal value at a surface intersection point $ p(t)$, i.e. with \(f(p(t)) = 0,\) that is, the point $ p(t) $ is on the zero-level set of the \(SDF (x)\).
保证与SDF为0的采样点,贡献最大
Occlusion-aware.(遮挡的识别和处理) Given any two depth values $t0 $ and $t1 $ satisfying \(f(t0) = f(t1), w(t0) > 0, w(t1) > 0\), and, $ t0 < t1$, there is $ w(t_0) > w(t_1)$. That is, when two points have the same SDF value (thus the same SDF-induced S-density value), the point nearer to the view point should have a larger contribution to the final output color than does the other point.
距离相机越近的采样点贡献越大 (SDF相同的情况下)
Naive solution
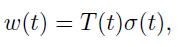
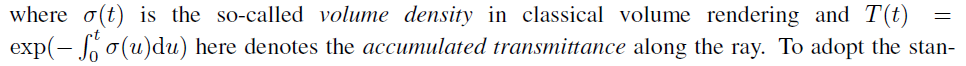
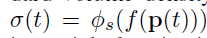
Our solution
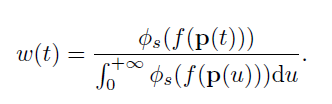
Unbiased but not occulusion-aware. 当光线穿过两个平面时, SDF函数 \(f\) 有两个零点,导致 \(w(t)\) 有两个相同峰值.
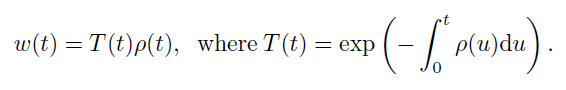
How we derive opaque density
经过复杂的数学推导,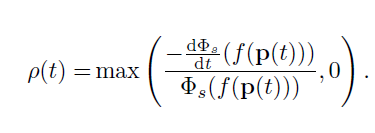
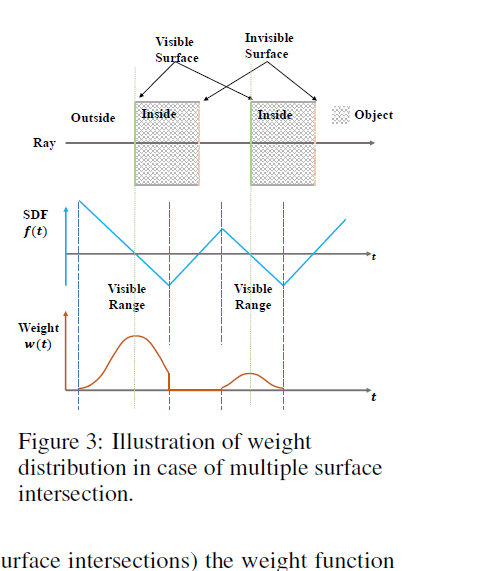
在写出体渲染的离散化写出:
`<img src="https://cdn.jsdelivr.net/gh/mxfg-incense/picture@main/test/202305261905780.png" alt="image-20230526190533946" style="zoom:67%;" />`Training
不依赖其他监督,只依赖颜色
损失函数

Hierarchical sampling.
我们首先沿着光线均匀采样64个点,然后我们迭代地进行4次重要性采样.只保留一个 fine NN, 第一次采样的概率基于 S-density \(\phi_s(f(x))\) ,\(s\) 是固定的, 第二次采样时学习后的 \(s\).