
一文搞懂字符编码
字符集和编码
字符集从字符到一个数字的映射。编码是一种规则,即如何将这个字符转变为二进制数。
ASCLL
计算机处理字符总是需要将其变为一个个 bit 所以最开始的字符集是ASCLL 码,将不同的英文字母,数字,以及控制字符映射到 8-bits 中。一开始 ASCLL 码只用到了 0 - 127。后来新增加了扩展 ASCLL 码, 利用了 128 - 255 剩下的一半字符。当称为 ASCLL 集的时候作为一种字符集,ASCLL 码时,是一种编码规则。
GB
GB 2312
GB2312 是一种中文的字符集,分区管理, 共计 94 个区, 每个区含 94 个位,共8836 码位。 码位按照按照区,行,列一次决定,比如「侃」字在 57 区 0 行 9 列, 码位就是 5709,十六进制为 0x39 0x09 分别加上 0xA0 得到 0xD9 和 0xA9 ,得到最终的 GB2312 为 0xD90xA9 。 加 0xA0 的目的可能使得高位和低位的值都大于 127, 向下兼容 ASCLL 码。当机器遇到连续两位大于 127 的 byte 时就能以此区分究竟是 ASCLL 码还是 GB2312 码。 GB2312 是双字节编码,为了与 ASCII 码区分开,字节的第8位必须是1,所以GB2312是8位编码。所以至少要从 0x80 128, 1000 0000) 开始吧,但是根据上面的规定,0x80 - 0x9f 要留给控制块,所以只能从 0xA0 开始咯。那为什么 GB2312 编码不是从 0xA0 开始,而是 0xA1 开始呢? 因为 0xA0 正好是图形块的空格,所以就从 0xA1 编码,这就是 0xA0 的由来
GBK
拓展,不规定低位大于 127 ,新增近 20000 个汉字符号。对应的字符编码叫 GBK 码
GB18030
新增少数民族文字
Unicode
是一个规则,包含字符集和对应的编码规则。把世界上所有的字符放在一起。
UCS-2 字符集
0x0000 - 0xFFFF ,可表示 65536 个字符。这里只是一个字符集,并不算真正意义上的编码。
UCS-4 字符集
0x00000000 - 0xFFFFFFFF , 可表示 43 亿字符。
缺点
储存空间过大
UTF-8 编码
每次传送 8 位 数字,而且可变长,节省流量和内存空间,是目前最广泛使用的编码规则

编码的应用举例
- 在计算机内存中是使用 Unicode 字符集, 当进行文本编辑时保存之前时用的 Unicode 数据。但是当数据写入磁盘的时候就和操作系统有关了,Linux 下是 UTF-8,在 Windows 下使用 GBK 编码。 比如写入一个文本文件时, 使用 UTF-8 编码 , 自然当打开文件时也应该默认使用 UTF-8 解码,在转为 Unicode 数据在内存里。 比如当使用 Python的open( ) 函数时,是内存中的进程与磁盘的交互,而这个交互过程中的编码格式则是使用操作系统的默认编码( Linux 为 utf-8,Windows 为 gbk)
- 而当编译器读取.py 文件时,需要将储存好的 Bytes 数据解码。Python 2 默认 ASCLL 码, 而Python 3 默认 UTF-8 编码。 所以当用 python 2 执行含有中文字符串的文件时会解码错误。于是在开头加行
\#-*-coding:utf-8-*-
Python 2
编码过程:写的代码通过 utf-8 写入,再通过解释器将其 Bytes 转换为另外编码形式的的 Bytes, utf-8 向下兼容 ASCLL。
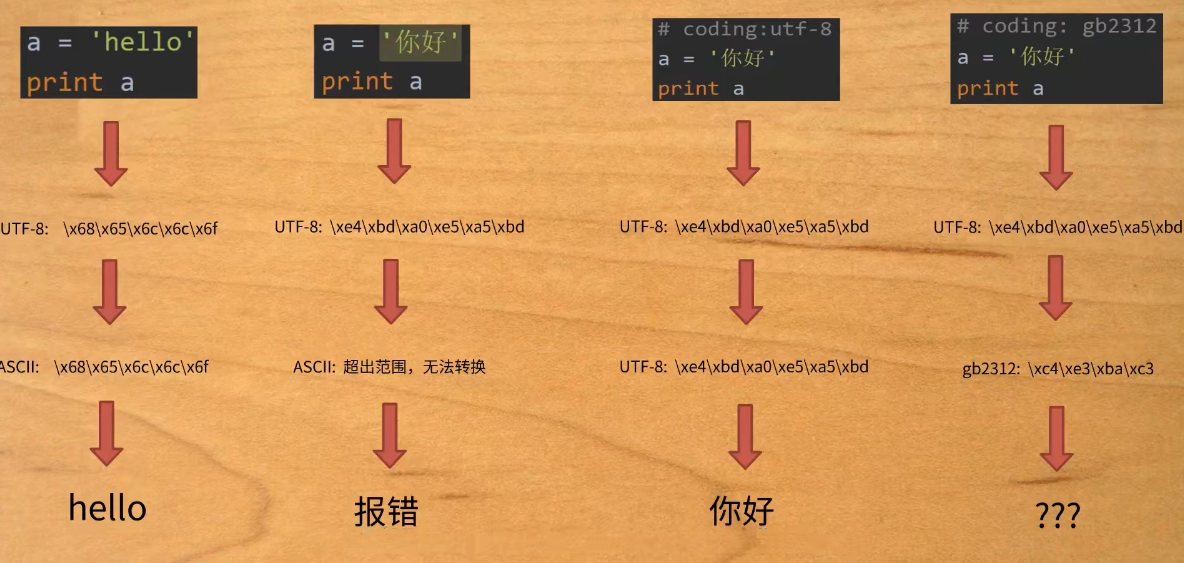
以上的数据都是以 bytes 形式存储的,在Python 2 中成为 str 类型。通过 print repr(a) 来查看内存中储存的形式。如果在字符串前面加上 u str = u'你好',则 u 后面的字符串通过 Unicode 加载进内存。 这种类型称为为 Unicode

Unicode 和 str 类型的转换
其实 str 就是 Bytes ,就是将Unicode 进行编码后的到的结果。

1 | # coding : utf-8 |
Python 3
默认以 Unicode 从硬盘中加载进内存。
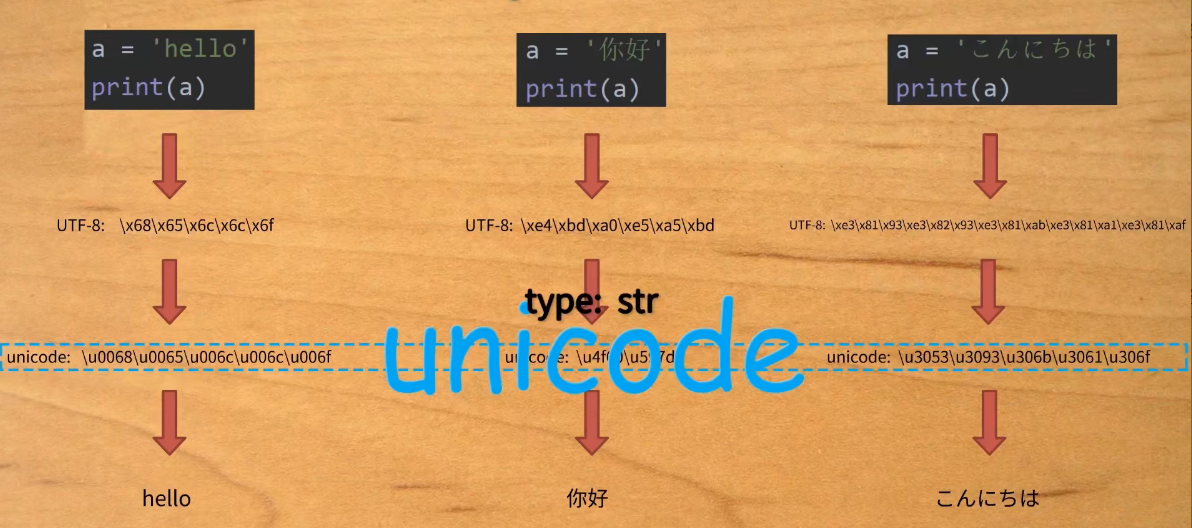
表示 bytes 内容, str = b'你好'
1 | a = "你好" |
将 Bytes 解码为 Unicode
1 | a = b'\xe4\xbd\xa0' |
参考
https://www.bilibili.com/video/BV1XK4y1t7D4?share_source=copy_web