
zero
组会
- zero to three 跑代码
- magic 123 利用 depth 效果差
- 缺口补全
- 陶片生成陶器
- 定期组会,周四下午五点
- Organization
- Threestudio Zero 123, 2T SSD
| description:" " |
计算 \(itn\) 次 logistic 映射, 具有如下形式:
\[ x_{n+1} = r x_n (1 - x_n) \]
Baseline 代码如下: 1
2
3
4
5
6
7
8
9
10
11
12double it(double r, double x, int64_t itn) {
for (int64_t i = 0; i < itn; i++) {
x = r * x * (1.0 - x);
}
return x;
}
void itv(double r, double* x, int64_t n, int64_t itn) {
for (int64_t i = 0; i < n; i++) {
x[i] = it(r, x[i], itn);
}
}
简单的想法是将 itv 中的 for 循环并行化,每次 it 并行计算 8 个 x. 代码如下:
1 | __m512d r_vec; |
编译指令为: 1
g++ -O3 -fopenmp -avx512f
这个度量指标表示由于核心与除法器无关的问题而导致应用程序停滞的周期的比例。例如,附近指令之间存在大量数据依赖,或者一系列指令过度加载特定端口。下面子项代表, CPU 在所有执行端口上每个周期执行了微操作的周期的占比。
但是这样的优化还是不够,丢尽 Vtune 中发现 microarchitecture Exploration 指标有些可优化的地方,比如:Port Utilization 在 Cycle of 1 Port Utilized. 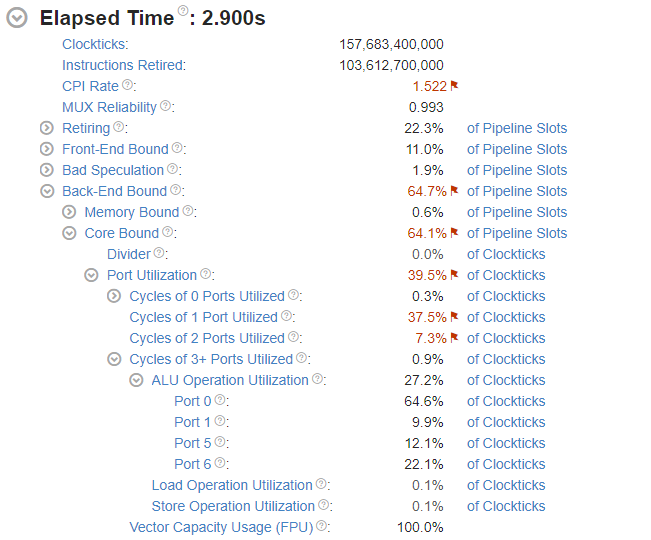 但感觉还是没看懂,但是大概是 pipline 的程度不够,因为每个线程的每次迭代只有一个 SIMD 指令再跑,并行化程度不够.
但感觉还是没看懂,但是大概是 pipline 的程度不够,因为每个线程的每次迭代只有一个 SIMD 指令再跑,并行化程度不够.
最终,就是将 itv 中的 for 循环展开,每次迭代并行计算 8 个 向量. 这样流水线至少可以有两个 SIMD 指令在跑,实测 BLOCK_SIZE = 16 性能差不多. 代码如下: 没有手写 SIMD 是因为编译器已经自动优化了. 如果想查看编译器的优化报告,编译时加上参数 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
void it(double* x, double r, int64_t itn) {
for (int64_t i = 0; i < itn; i++) {
for (int j = 0; j < BLOCK_SIZE; j++) {
x[j] = r * x[j] * (1.0 - x[j]);
}
}
}
void itv(double* x, double r, int64_t n, int64_t itn) {
for (int64_t i = 0; i < n; i+=BLOCK_SIZE) {
it(&x[i], r, itn);
}
}-fopt-info-optimized 可查看优化报告.
https://stackoverflow.com/questions/67818011/is-there-a-reasonable-way-to-make-an-executable-binary-file-by-hand-using-only
cl.exe is complier and linker in msvc
CmakeList.txt 是build 和 makefile 的区别
https://medium.com/nerd-for-tech/an-overview-of-pipeline-parallelism-and-its-research-progress-7934e5e6d5b8
什么是nodes
microopenration: , micro-operations (also known as micro-ops or μops, historically also as micro-actions[2]) are detailed low-level instructions used in some designs to implement complex machine instructions (sometimes termed macro-instructions in this context).[3]: 8–9
微架构管道
retired unit
O3 自动向量化 Memory Aliasing
"GFLops" 是一个缩写,代表每秒的“Giga Floating-point Operations per second”,即每秒十亿次的浮点运算。这通常用于衡量计算机系统或算法的性能,特别是在涉及大量浮点运算的科学计算和机器学习任务中。
https://en.algorithmica.org/hpc/algorithms/matmul/
g++ -O3 -fopt-info-optimized=report.txt your_source.cpp
latency and throughput